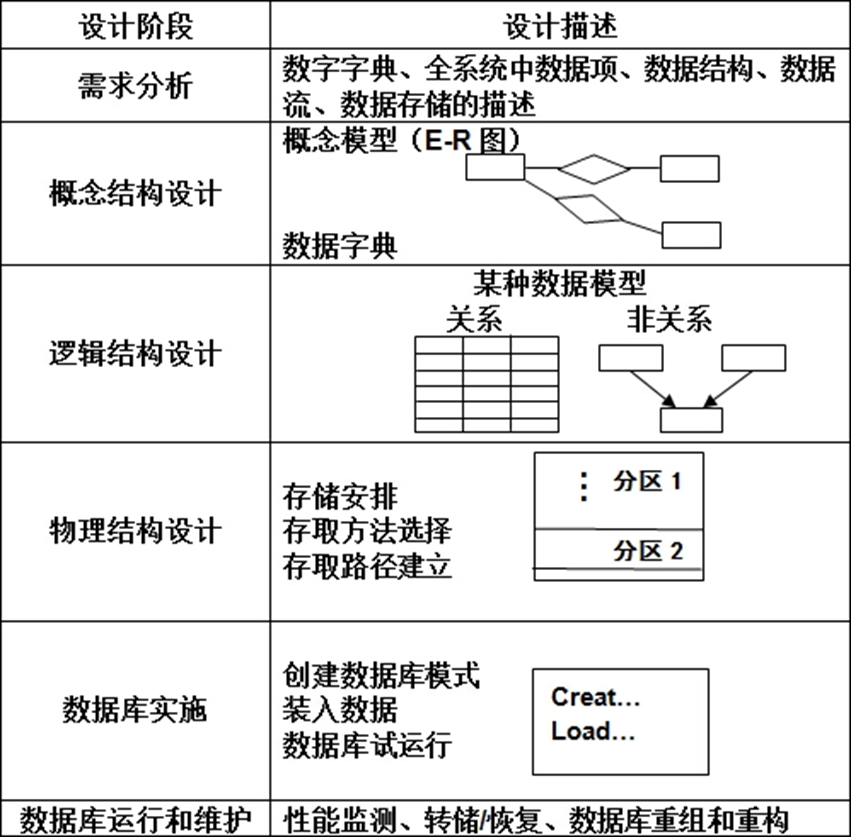
数据库系统---数据库设计
前期规划
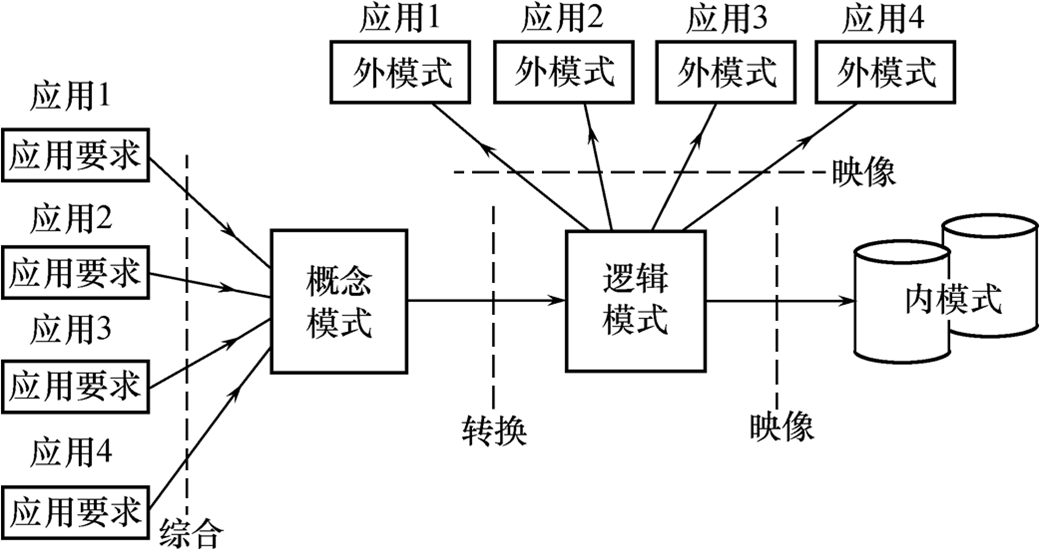
外模式:各类Application
逻辑模式:各类数据库管理系统
内模式:各类操作系统与电脑硬件开发
需求分析
综合各个用户的应用需求
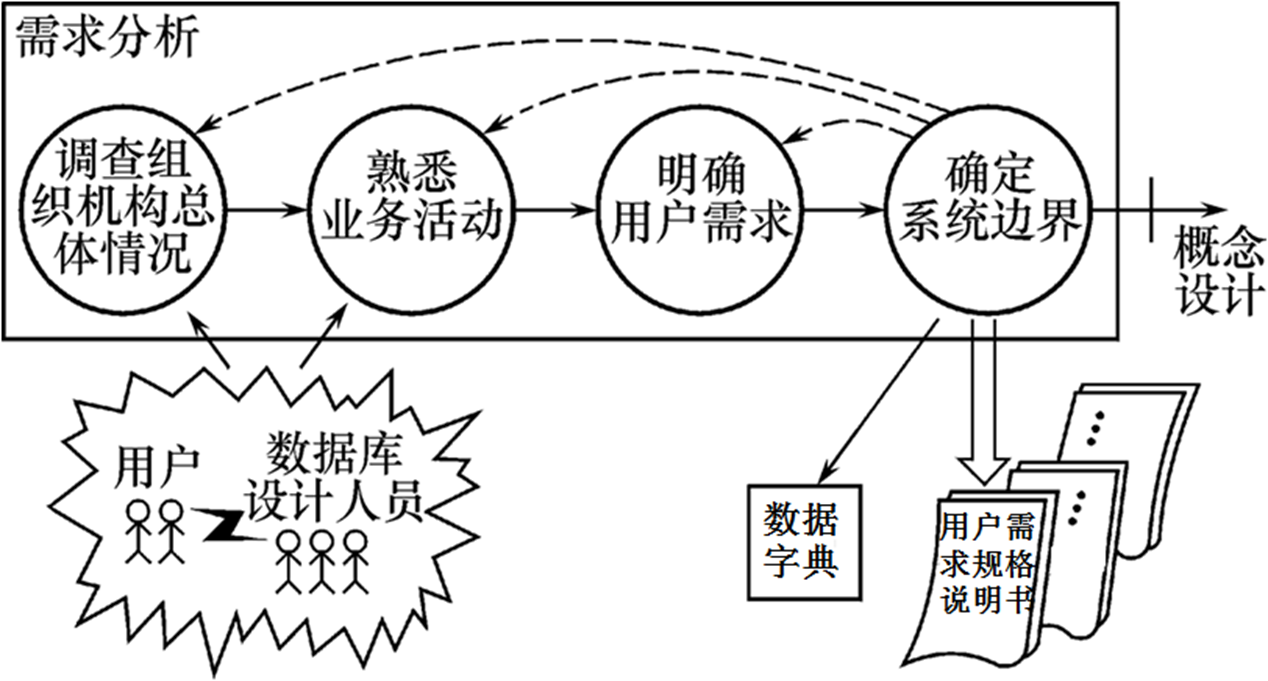
数据流图(DFD)
数据字典
内容:
数据项
数据结构
数据流
数据存储
处理过程
数据项
数据项是不可再分的数据单位
对数据项的描述
数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系,数据项之间的联系}
“取值范围”、“与其他数据项的逻辑关系”定义了数据的完整性约束条件,是设计 数据检验功能的依据
可以用关系规范化理论为指导,用数据依赖的概念分析和表示数据项之间的联系
数据结构
数据结构反映了数据之间的组合关系。
一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成。
对数据结构的描述
数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
数据流
数据流是数据结构在系统内传输的路径。
对数据流的描述
数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}
数据流来源:说明该数据流来自哪个过程
数据流去向:说明该数据流将到哪个过程去
平均流量:在单位时间(每天、每周、每月等)里的传输次数
高峰期流量:在高峰时期的数据流量
数据存储
数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。
对数据存储的描述
数据存储描述={数据存储名,说明,编号,输入的数据流 ,输出的数据流,组成:{数据结构},数据量,存取频度,存取方式}
存取频度:每小时、每天或每周存取次数,每次存取的数据量等信息
存取方法:批处理 / 联机处理;检索 / 更新;顺序检索 / 随机检索
输入的数据流:数据来源
输出的数据流:数据去向
处理过程
处理过程的具体处理逻辑一般用判定表或判定树来描述。数据字典中只需要描述处理过程的说明性信息
处理过程说明性信息的描述
处理过程描述={处理过程名,说明,输入:{数据流}, 输出:{数据流},处理:{简要说明}}
简要说明:说明该处理过程的功能及处理要求
功能:该处理过程用来做什么
处理要求:处理频度要求,如单位时间里处理多少事务,多少数据量、响应时间要求等
处理要求是后面物理设计的输入及性能评价的标准
概念结构设计
形成独立于机器特点,独立于各个数据库管理系统产品的概念模式(E-R图)
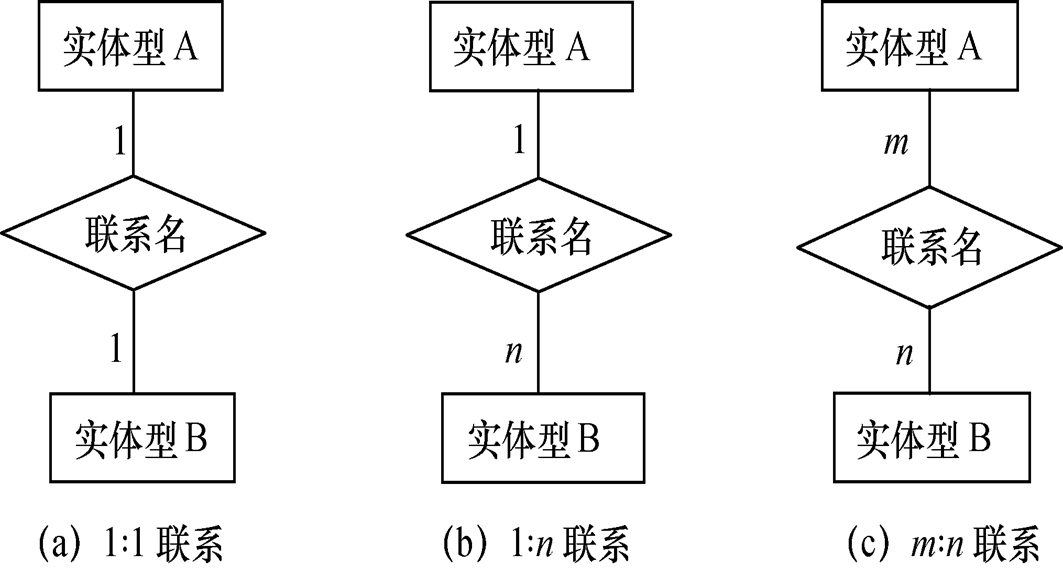
三种联系
两个实体型之间的联系:
一对一联系(1∶1)
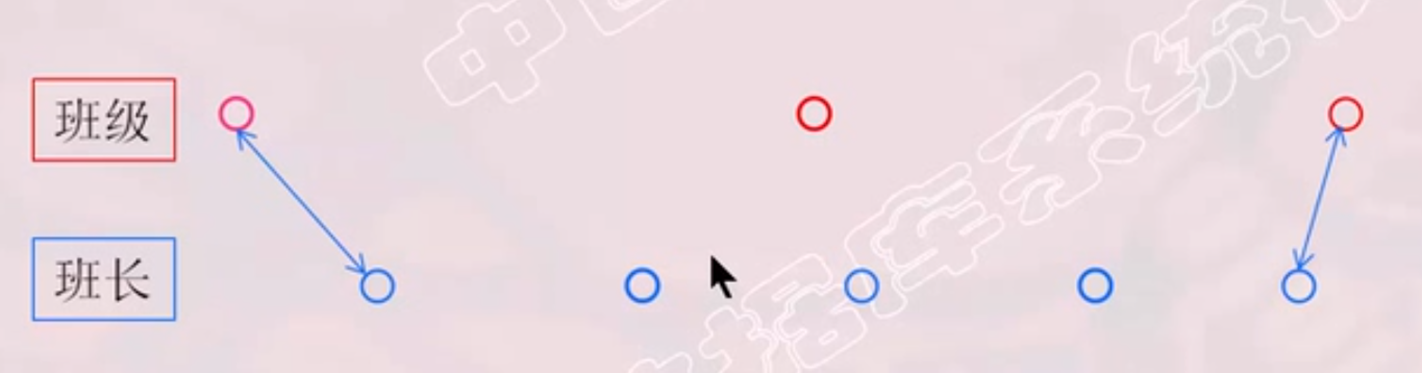
一对多联系(1∶n)
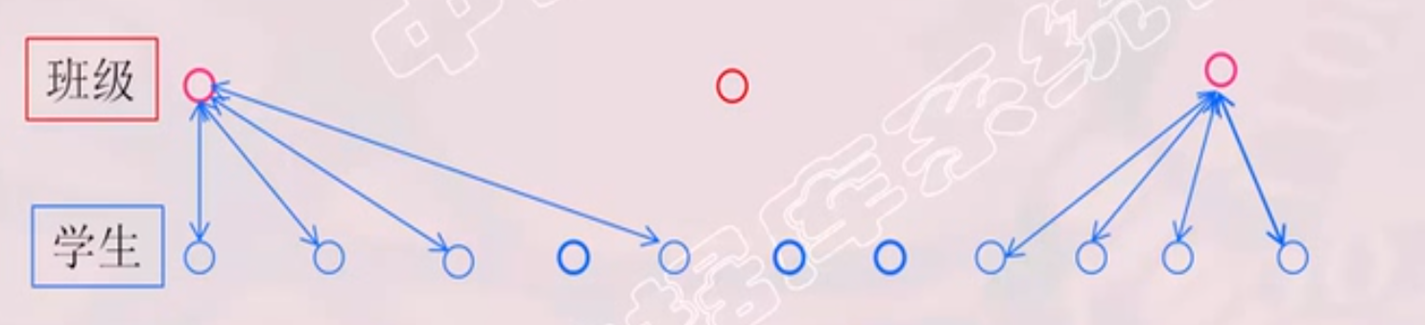
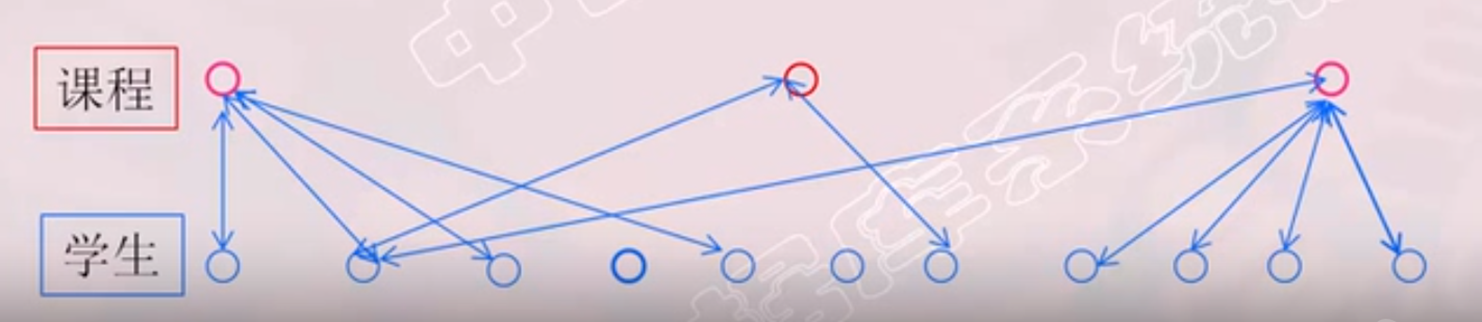
多对多联系(m∶n)
E-R图
实体型:用矩形表示,矩形框内写明实体名。
属性:用椭圆形表示,并用无向边将其与相应的实体型连接起来。
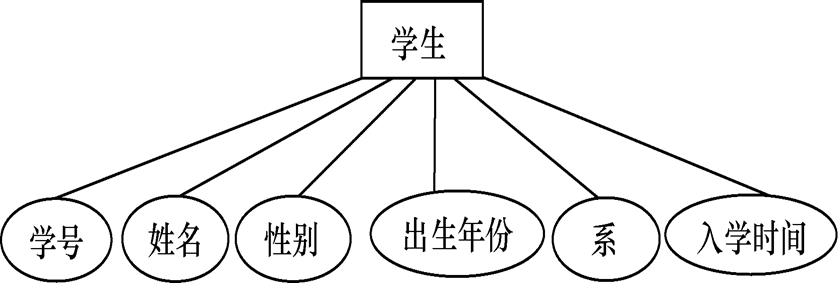
联系:用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体型连接起来,同时在无向边旁标上联系的类型(1∶1,1∶n或m∶n)。
联系可以具有属性
实体属性图
分E-R图
整体E-R图
逻辑结构设计
1. 首先将E-R图转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式
2. 然后根据用户处理的要求、安全性的考虑,在基本表的基础上再建立必要的视图(View),形成数据的外模式
E-R图向关系模型的转换
转换原则:
1. 一个实体型转换为一个关系模式
2. 实体型间的联系有以下不同情况
(1)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。可拆可不拆
① 转换为一个独立的关系模式
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的候选码:每个实体的码均是该关系的候选码
R(左实体主码,右实体主码,关系属性)
主码:左实体主码或右实体主码,二选一
②与某一端实体对应的关系模式合并
合并后关系的属性:加入对应关系的码和联系本身的属性
合并后关系的码:不变
左实体(左实体主码,左实体属性,右实体主码,关系属性)
多两列
主码:左实体主码
(2)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。可拆可不拆
①转换为一个独立的关系模式
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的码:n端实体的码
R(1端实体主码,N端实体主码,关系属性)
主码:N端实体当主码
②与n端对应的关系模式合并
合并后关系的属性:在n端关系中加入1端关系的码和联系本身的属性
合并后关系的码:不变
可以减少系统中的关系个数,一般情况下更倾向于采用这种方法
把1端往N端合并
R(N端实体主码,N端实体属性,1端实体主码,关系属性)
主码:N端实体当主码
(3)一个m:n联系转换为一个关系模式必须拆
关系的属性:与该联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合
R(左实体主码,右实体主码,关系属性)
主码:左实体主码和右实体主码,共同主码
(4)三个或三个以上实体间的一个多元联系转换为一个关系模式。
关系的属性:与该多元联系相连的各实体的码以及联系本身的属性
关系的码:各实体码的组合
有就拆,1对1二选一,1对N选多的,N对M共同主码
关系模式设计
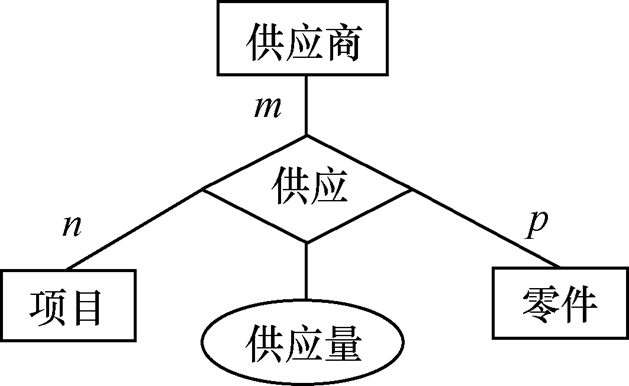
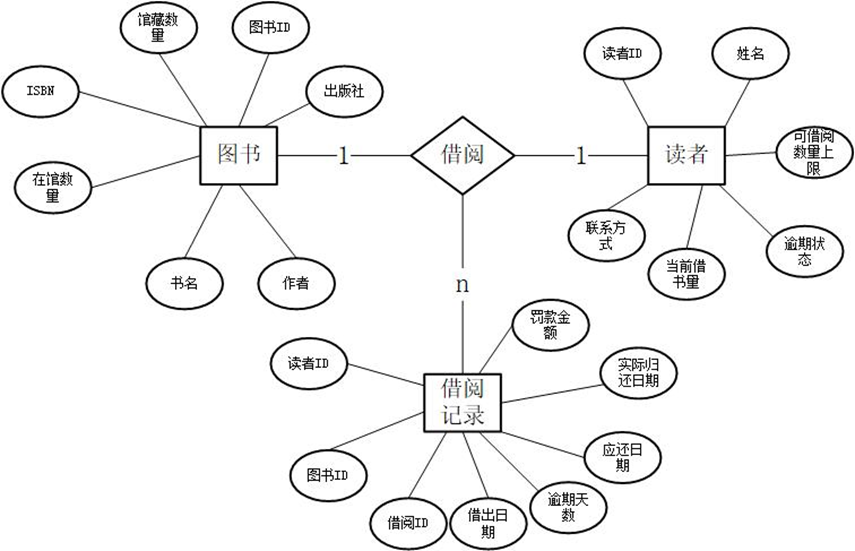
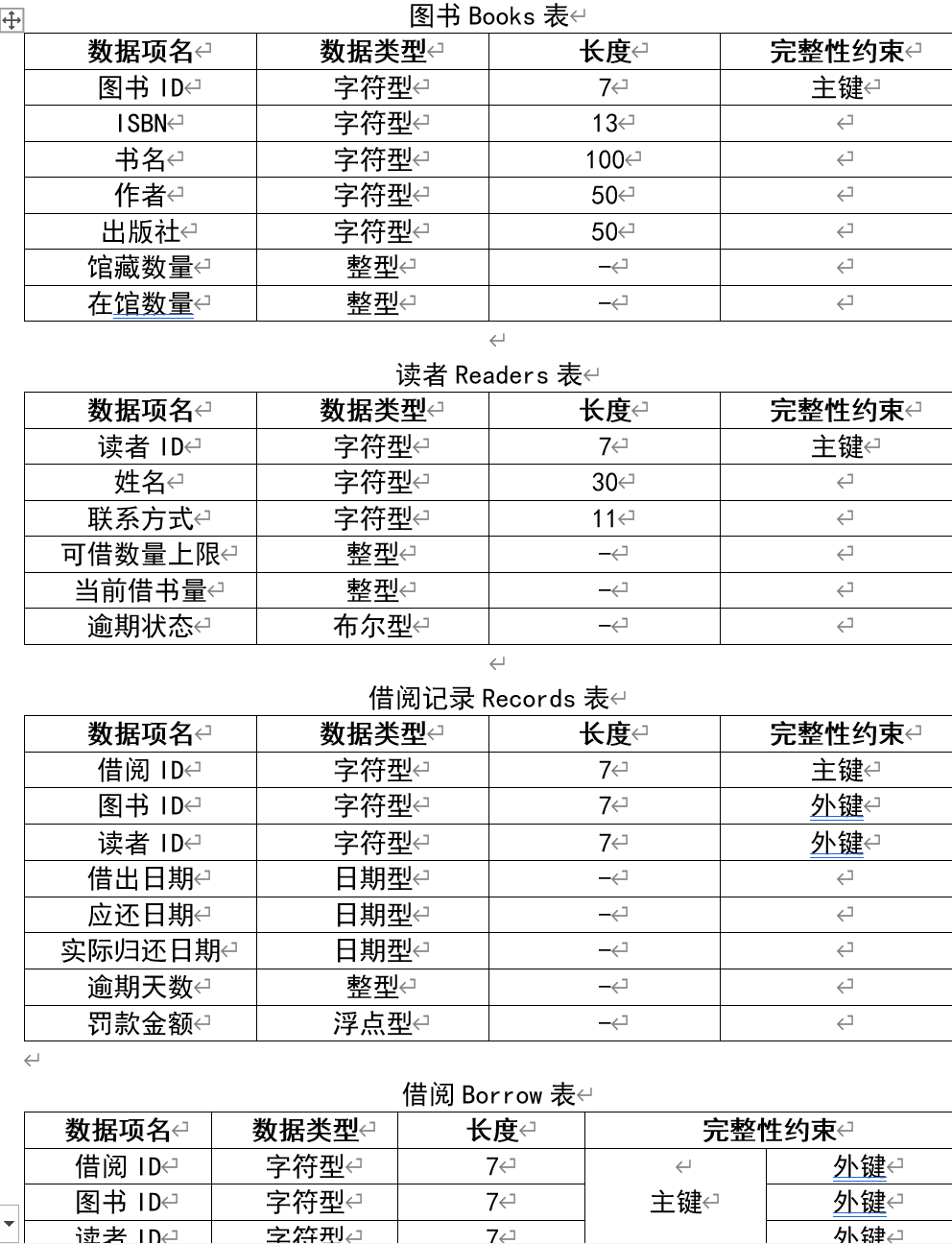
图书Books(图书ID, ISBN, 书名, 作者, 出版社, 馆藏数量, 在馆数量)
读者Readers(读者ID, 姓名, 联系方式, 可借数量上限, 当前借书量, 逾期状态)
借阅记录Records(借阅ID, 读者ID, 图书ID, 借出日期, 应还日期, 实际归还日期, 逾期天数, 罚款金额)
借阅Borrow(图书ID, 读者ID,借阅ID)
数据类型定义
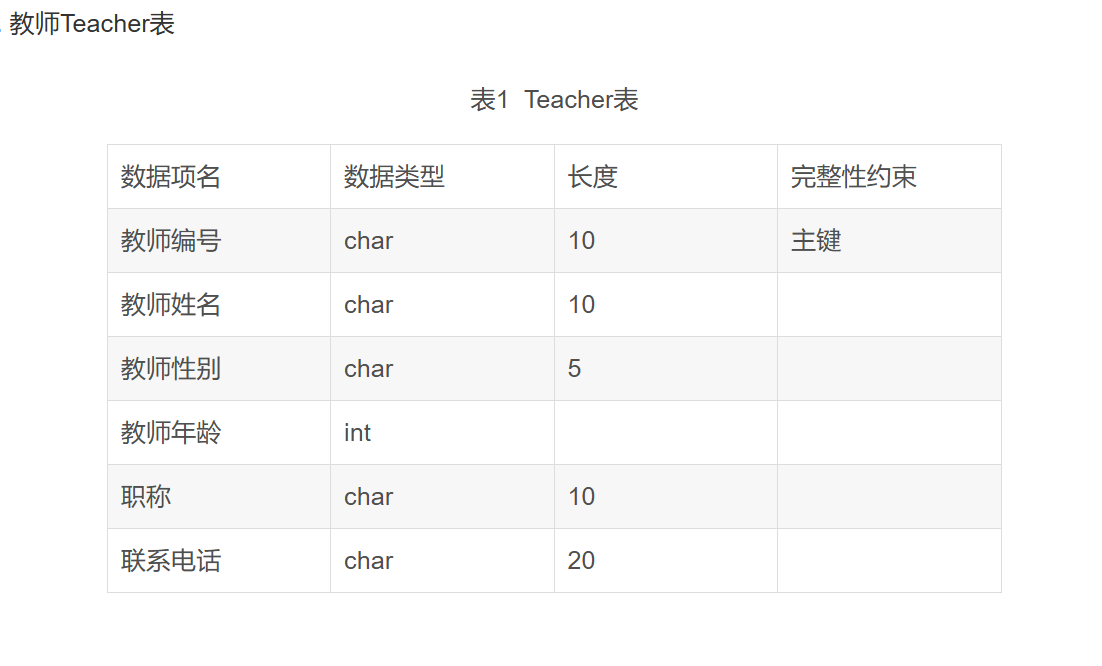
实体表:
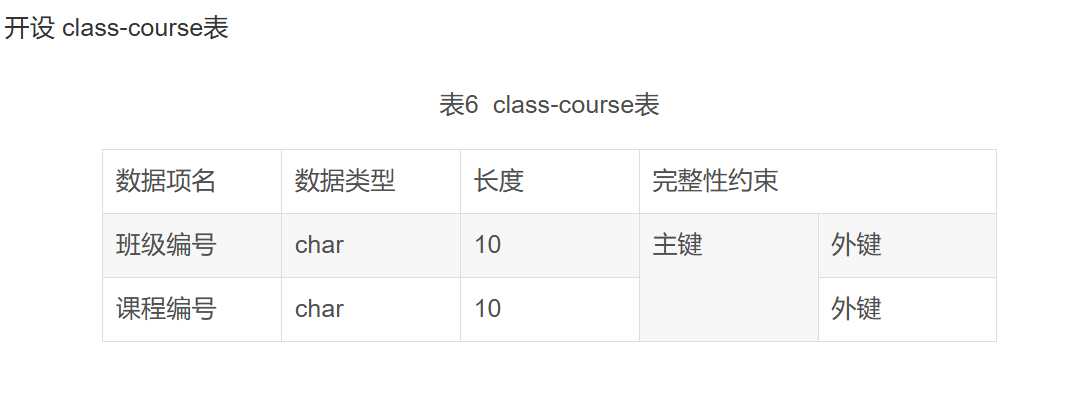
关系表:
物理结构设计
根据数据库管理系统特点和处理的需要,进行物理存储安排,建立索引,形成数据库内模式
选择存储方法
数据库文件的存储技术,常用的存取方法有三类:
B+树索引存取方法
Hash索引存取方法
聚簇存取方法
选择索引存取方法的一般规则
如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(或这组)属性上建立索引(或组合索引)
如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引
如果一个(或一组)属性经常在连接操作的连接条件中 出现,则考虑在这个(或这组)属性上建立索引