向量数据库选型建议
向量数据库选型建议
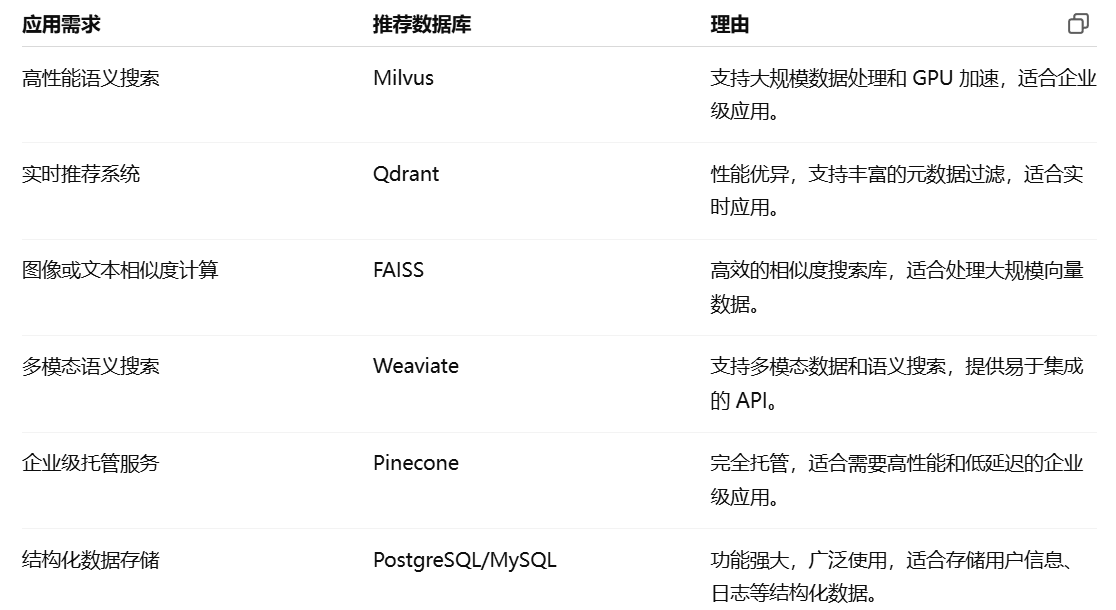
向量数据库专为存储和检索高维向量数据而设计,适用于语义搜索和问答系统。以下是几种主流的向量数据库及其特点:知乎专栏+2CSDN博客+2百度智能云+2
1. Milvus
特点:开源、支持大规模数据处理、提供多种索引类型(如 IVF、HNSW)、支持 GPU 加速。
适用场景:需要高性能和可扩展性的企业级应用,如检索增强生成(RAG)系统。
参考资料:根据官方案例使用 Milvus 向量数据库打造问答 RAG 系统 。zilliz.com.cn+2Amazon Web Services, Inc.+2CSDN博客+2CSDN博客+1知乎专栏+1
2. Qdrant
特点:使用 Rust 编写,性能优异,支持 HNSW 索引,提供丰富的元数据过滤功能。
适用场景:实时语义搜索、推荐系统、多模态数据处理等。
3. FAISS
特点:由 Meta 开发的高效相似度搜索库,支持多种索引算法,适合处理大规模向量数据。
适用场景:图像检索、推荐系统、文本相似度计算等。
4. Weaviate
特点:开源的云原生向量数据库,支持多模态数据和语义搜索,提供 GraphQL API,便于集成。
适用场景:多模态语义搜索、知识图谱构建、智能问答系统等。
5. Pinecone
特点:完全托管的向量数据库,专为高性能、低延迟的近似最近邻搜索而设计。
适用场景:企业级语义搜索、RAG 系统、推荐引擎等。
结构化数据库选型建议
对于存储用户信息、日志、权限等结构化数据,以下数据库是常见的选择:
1. PostgreSQL
特点:功能强大的开源关系型数据库,支持复杂查询和事务处理。
适用场景:需要强一致性和复杂查询的应用。
2. MySQL
特点:广泛使用的开源关系型数据库,易于部署和维护。
适用场景:中小型应用,或对性能要求不高的场景。
License:
CC BY 4.0