智能应答系统
架构图
mathematica复制编辑
┌─────────────────────────────────────────── ─┐
│ 用户界面层 │
│ - Web / 移动 App / API 接口 / 聊天窗口 │
└────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 应用服务层(FastAPI) │
│ - 请求接收 & 认证 │
│ - 日志收集 & 异常处理 │
└────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 问题解析与意图识别(NLU) │
│ - 分词、纠错、实体识别、问题分类 │
└────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 多轮对话管理(Dialog Manager) │
│ - 用户状态管理 │
│ - 上下文存储(Redis / 自定义记忆系统) │
└────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 智能问答核心(QA Core) │
│ ┌──────────────┐ ┌──────────────────┐ │
│ │ 检索式问答模块│ │ 生成式问答模块(RAG) │
│ └──────────────┘ └──────────────────┘ │
└────────────────────────────────────────────┘
│
┌────────────┴────────────┐
▼ ▼
┌─────────────────┐ ┌──────────────────────────────┐
│ 向量数据库(IR) | │ 大语言模型(LLM)推理服务 |
│ Milvus │ │ GLM-4 │
└─────────────────┘ └──────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 知识源 / 数据接入层 │
│ - 文档(PDF, Word, 网页) │
│ - 数据库(MySQL, MongoDB) │
│ - 知识图谱(Neo4j) │
│ - 实时业务API │
└────────────────────────────────────────────┘问题解析与意图识别(NLU):
意图识别(Intent Recognition):确定用户话语的目的或意图,例如在对话系统中识别用户是想预订机票还是查询天气。RoBERTa FastText
命名实体识别(Named Entity Recognition, NER):识别文本中的专有名词,如人名、地名、组织机构等。BERT-BiLSTM-CRF
情感分析(Sentiment Analysis):判断文本表达的情感倾向,如积极、消极或中性。
共指消解(Coreference Resolution):识别文本中指代关系,例如确定“他”指的是前文提到的哪个人。
语义角色标注(Semantic Role Labeling):分析句子中各个成分的语义角色,如动作的执行者、受益者等。
DM的主要任务包括:
对话状态跟踪(Dialog State Tracking, DST):持续更新和维护对话的上下文信息,如用户的意图、已提供的信息、待确认的槽位等。
对话策略管理(Dialog Policy Management):根据当前的对话状态,决定系统的下一步动作,如提问、确认、提供信息等。
上下文管理:确保系统能够理解和利用对话历史,处理指代消解、话题切换等问题。
向量数据库:
向量数据库在智能问答系统中不仅是信息检索的核心组件,还在提升系统的语义理解能力、扩展性、多模态处理能力和个性化服务等方面发挥着重要作用。
技术线路
智能问答系统作为人工智能技术的重要应用方向,其构建依赖于系统性且高度集成的技术方案。整体系统架构通常包含用户交互层、问题处理层、知识库及结果呈现层等模块。其中,用户交互层负责接收用户输入的文本或语音,并以友好方式反馈答案,确保良好的人机交互体验;问题处理层则涵盖自然语言处理、机器学习和逻辑推理技术,是解析用户问题并识别意图的关键环节;知识库部分主要存储结构化与非结构化数据,如领域专业知识、事实信息和经验规则,为问答引擎提供支持;而结果呈现层则将处理结果通过文本、语音或图像等多模态方式直观展示给用户。
在关键技术选型方面,自然语言处理技术是系统的基础。中文处理方面,通常采用Jieba或HanLP进行分词,英文文本则结合SpaCy进行预处理;拼写纠错(CSC Chinese Spelling Correction)可使用ChatGLM或具备拼音感知能力的Transformer模型,命名实体识别则基于BERT-BiLSTM-CRF架构实现高精度抽取。意图识别方面,则常选用RoBERTa进行深度语义分类,FastText则适用于轻量级场景。
对于信息检索类问答,需构建高效的检索式QA模块。文档向量化方面,采用如OpenAI的text-embedding-3-large或bge-large-zh等先进模型生成语义向量,向量数据库则可选FAISS、Milvus或Qdrant以实现高效的相似度搜索。通过将BM25与向量检索相结合,实现Hybrid Search策略,可有效提升复杂问题的召回率与精度。
在生成式问答方面,系统通常基于RAG(Retrieval-Augmented Generation)架构构建,通过LangChain或LlamaIndex等框架整合外部知识与大语言模型(如GPT-4.5、Claude 3、Gemini 1.5),以增强系统的生成能力;同时,亦可离线部署如ChatGLM3或Yi-1.5等本地模型以满足数据私有化需求。对于多轮对话场景,需引入对话状态追踪(Dialog State Tracking)机制,通过Redis等内存数据库记录并维护上下文状态,结合Rasa等轻量级对话系统框架,或使用LangChain构建复杂流程控制,实现稳定的上下文管理与用户意图连续识别。知识接入层面,系统应支持多种数据源接入,如PDF、Word文档、网页爬虫或结构化数据库(MySQL、MongoDB等),并可结合知识图谱技术(如基于Neo4j构建的图谱)以实现复杂推理能力,进一步借助KG-BERT或GraphRAG等图神经问答模型提升系统的推理能力与语义理解深度。
在系统开发与部署流程方面,需首先进行详尽的需求分析,明确系统所支持的问答类型(如FAQ、事实型、任务型等);随后进行数据准备,包括问答对的采集、清洗、标注及预处理。模型训练阶段需根据任务特点选择合适的深度学习模型,并通过交叉验证防止过拟合。接口开发方面推荐设计RESTful API或GraphQL接口,确保系统各模块间解耦与扩展性。系统部署通常采用Docker进行容器化封装,并结合Kubernetes实现弹性伸缩与负载均衡,以支持大规模部署和高可用性需求。系统上线后还需持续监控运行性能,并通过模型蒸馏、量化、索引优化等手段提升响应效率与资源利用率。通过用户反馈机制不断迭代模型与系统功能,是保障长期运行效果与用户满意度的关键。
展望未来,智能问答系统将朝多模态、情感感知、自适应学习与跨语言等方向发展。多模态问答将集成图像、音频等多种信息源,提升系统的理解与交互维度;情感识别模块的引入将使系统能够感知用户情绪状态并调整回答策略,提升交互自然性;自适应学习机制则使系统在长期使用过程中自动调优参数与知识结构,提升问答准确性与个性化水平;同时,跨语言能力将扩展系统应用于多语种环境,支持全球用户的自然语言问答需求,为通用人工智能的发展奠定基础。
模型选型
vLLM:高性能推理引擎
vLLM 是由 UC Berkeley Sky Computing Lab 开发的开源推理引擎,专为高吞吐量和内存效率优化。其核心特性包括:
PagedAttention:借鉴操作系统的分页机制,实现高效的注意力机制内存管理,显著提升推理吞吐量,尤其在处理长文本时表现优异。
连续批处理(Continuous Batching):动态合并多个请求,提升并发处理能力,适用于高并发场景。
广泛的模型支持:原生支持 Hugging Face 上的多种模型架构,包括 ChatGLM、LLaMA、Baichuan、Falcon 等,便于集成和部署。 GitHub
多种量化支持:支持 GPTQ、AWQ、INT4、INT8 等量化方式,降低模型部署成本。vLLM+2GitHub+2nm-vllm.readthedocs.io+2
适用场景:适合需要高性能推理的应用,如实时问答系统、聊天机器人和大规模文本生成任务。
ChatGLM3 / GLM-4 系列:中文优化的开源大模型
ChatGLM3 和 GLM-4 系列是清华大学团队开发的开源大模型,针对中文任务进行了深度优化:
ChatGLM3-6B:在理解能力上表现优异,甚至在某些中文理解任务上超过了 GPT-4(2023 年 3 月版本)。 Reddit
GLM-4 系列:包括 GLM-4、GLM-4-Air 和 GLM-4-9B,预训练数据涵盖中英文及其他 24 种语言,支持多模态输入(如图像)和工具调用(如浏览器、Python 解释器),在多项基准测试中表现出色。 arXiv
适用场景:适合中文问答系统、多模态交互和需要工具调用的复杂任务。
GPT-4:通用性能领先的闭源模型
GPT-4 是 OpenAI 开发的闭源大型语言模型,具有强大的通用性能:
多领域能力:在医学、法律、数学等多个领域的标准测试中表现优异,展示了卓越的理解和推理能力。 arXiv
多模态支持:GPT-4o 版本引入了图像和音频处理能力,扩展了模型的应用范围。
适用场景:适合需要高准确性和多领域知识的应用,如医疗问答、法律咨询和多语言翻译等。
模型对比总结
QA Core
RAG+
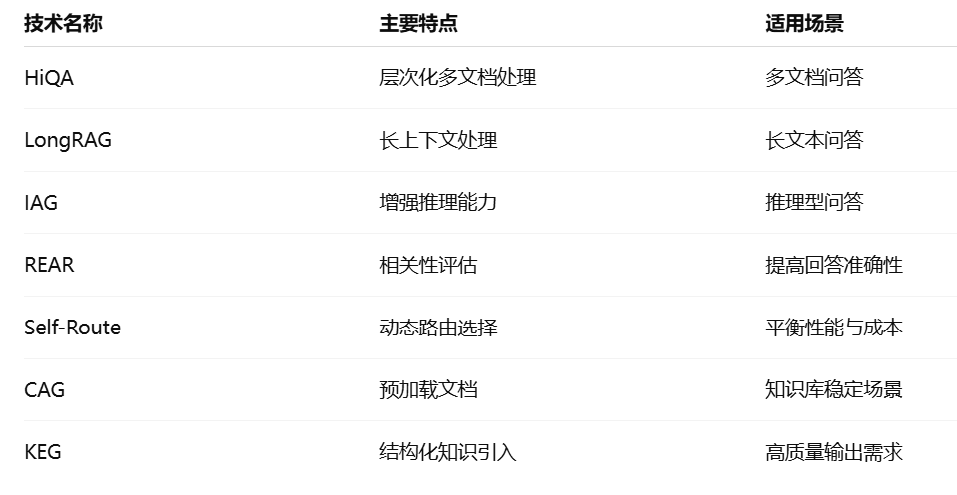
选型建议
高性能部署:如果您需要部署多个模型并追求高吞吐量,建议使用 vLLM 作为推理引擎,结合 Hugging Face 上的开源模型。
中文任务优化:针对中文问答或多模态交互任务,GLM-4 系列提供了良好的性能和灵活性。
高准确性需求:对于对准确性要求极高的应用,如医疗或法律领域的问答系统,GPT-4 是可靠的选择,但需考虑其闭源和成本因素。
NLU 与 NLP 的关系
自然语言处理(NLP)是一个广泛的领域,涵盖了语言的分析、理解和生成等多个方面。NLU 是 NLP 的一个子集,专注于语言的理解部分。具体来说,NLP 包括以下三个主要组成部分:
自然语言理解(NLU):使计算机能够理解人类语言的含义和意图。
自然语言生成(NLG):使计算机能够生成符合语法和语义的自然语言文本。
自然语言处理的其他任务:如语音识别、机器翻译、文本摘要等。
因此,NLU 是实现更高级别 NLP 应用(如智能对话系统)的基础。
Jieba或HanLP
如果项目对分词精度和 NLP 功能有较高要求,建议选择 HanLP;如果项目需要快速开发,且对分词精度要求不高,Jieba 是一个不错的选择。在实际应用中,也可以根据需要将两者结合使用,以发挥各自的优势。
Python入门:jieba库的使用_jieba python-CSDN博客
使用BERT + Bi-LSTM + CRF 实现命名实体识别_开源bert-bi-lstm-crf实体识别模型-CSDN博客